엣지 AI,로봇 AI 칩,5G-AI 칩 10종 비교 (2025년 기준)

2025년 현재, 전 세계 엣지 AI 반도체 시장은 다양한 기업들이 고성능과 저전력 솔루션을 앞세워 경쟁하고 있습니다. 아래는 주요 엣지 AI 칩 10종의 비교 표입니다:
🌐 전 세계 주요 엣지 AI 칩 10종 비교 (2025년 기준)
| 순위 | 칩 이름 | 제조사 | 최대 연산 성능 | 전력 소비 | 주요 적용 분야 | 특징 및 비고 |
| 1 | Jetson Orin Nano Super | NVIDIA | 약 70 TOPS | 약 15W | 로봇, 드론, 산업 자동화 | 소형 기업 및 개발자용 저가형 엣지 AI 솔루션 |
| 2 | Snapdragon X80 | Qualcomm | 약 45 TOPS | 약 10W | 스마트폰, 노트북, 자동차 | 5G 모뎀과 통합된 AI 처리 기능 |
| 3 | Ryzen AI 300 시리즈 | AMD | 최대 50 TOPS | 15~54W | 초박형 노트북, AI PC | Zen 5 아키텍처 기반의 고성능 NPU 탑재 |
| 4 | TPU Edge 시리즈 | 약 32 TOPS | 약 10W | IoT, 스마트 홈, 모바일 기기 | Google의 자체 설계 AI 가속기 | |
| 5 | SAKURA-II | EdgeCortix | 60 TOPS (INT8) | 8W | 자율주행, 국방, 스마트시티 | DNA 아키텍처 기반의 저전력 고성능 칩 |
| 6 | Tachy-BS402 | 디퍼아이(DeePerEye) | 공개되지 않음 | 공개되지 않음 | 의료 AI, 보안 감시, 공장 자동화 | X2X 통신 기반 SoC 간 분산 처리 아키텍처 |
| 7 | Chimera GPNPU | Quadric | 약 40 TOPS | 약 10W | 산업용 엣지 디바이스, 로보틱스 | 완전한 C++ 프로그래밍 가능 AI/ML 추론 솔루션 |
| 8 | Hailo-8 | Hailo | 26 TOPS | 2.5W | 비전 AI, 스마트 카메라, IoT | 초소형 폼팩터의 고효율 AI 프로세서 |
| 9 | Inferentia 2 | Amazon | 약 100 TOPS | 약 25W | 클라우드 기반 AI 추론 | AWS 전용 AI 추론 칩 |
| 10 | Granite Rapids-D | Intel | 최대 288 코어 | 약 150W | 5G 네트워크, 엣지 서버 | Xeon 기반의 엣지 컴퓨팅 특화 프로세서 |
🔍 요약 및 선택 가이드
- 고성능 엣지 AI 처리: NVIDIA의 Jetson Orin Nano Super와 AMD의 Ryzen AI 300 시리즈는 고성능을 요구하는 엣지 AI 애플리케이션에 적합합니다.위키백과+1월스트리트저널+1
- 저전력 및 소형 디바이스: Hailo-8과 Qualcomm의 Snapdragon X80은 저전력 소비와 소형 폼팩터를 필요로 하는 디바이스에 이상적입니다.마켓워치+1Hailo+1
- 산업 및 특수 목적: EdgeCortix의 SAKURA-II와 디퍼아이의 Tachy-BS402는 산업용 및 특수 목적의 엣지 AI 솔루션에 적합합니다.
- 클라우드 및 서버 기반: Amazon의 Inferentia 2와 Intel의 Granite Rapids-D는 클라우드 및 서버 기반의 대규모 AI 추론 작업에 최적화되어 있습니다.월스트리트저널+4위키백과+4Robotics & Automation News+4
각 칩의 선택은 사용자의 특정 요구 사항, 예산, 전력 소비 제한 및 애플리케이션에 따라 달라질 수 있습니다. 추가적인 정보나 특정 용도에 대한 추천이 필요하시면 알려주시기 바랍니다.
2025년 현재, 전 세계 엣지 AI 반도체 시장은 다양한 기업들이 고성능과 저전력 솔루션을 앞세워 경쟁하고 있습니다. 아래는 주요 엣지 AI 칩 10종의 상세 사양 비교입니다:
🌐 전 세계 주요 엣지 AI 칩 10종 상세 사양 비교 (2025년 기준)
| 순위 | 칩 이름 | 제조사 | 연산 성능 (TOPS) | 전력 소비 | 메모리 구성 | 인터페이스 | 주요 적용 분야 | 특징 및 비고 |
| 1 | Jetson Orin Nano Super | NVIDIA | 67 TOPS | 7~15W | 8GB LPDDR5 | PCIe Gen 3.0 x4 | 로봇, 드론, 산업 자동화 | 소형 폼팩터, 저가형 엣지 AI 솔루션 |
| 2 | Snapdragon X80 | Qualcomm | 약 45 TOPS | 약 10W | 통합 메모리 | 통합 인터페이스 | 스마트폰, 노트북, 자동차 | 5G 모뎀과 통합된 AI 처리 기능 |
| 3 | Ryzen AI 300 시리즈 | AMD | 최대 50 TOPS | 15~54W | 최대 32GB RAM | 다양한 인터페이스 | 초박형 노트북, AI PC | Zen 5 아키텍처 기반의 고성능 NPU 탑재 |
| 4 | TPU Edge 시리즈 | 약 32 TOPS | 약 10W | 8MB SRAM | USB 3.0 또는 mPCIe | IoT, 스마트 홈, 모바일 기기 | Google의 자체 설계 AI 가속기 | |
| 5 | SAKURA-II | EdgeCortix | 60 TOPS (INT8) | 8W | 최대 32GB LPDDR4 | PCIe Gen 3.0 x4/x8 | 자율주행, 국방, 스마트시티 | DNA 아키텍처 기반의 저전력 고성능 칩 |
| 6 | Tachy-BS402 | 디퍼아이(DeePerEye) | 공개되지 않음 | 공개되지 않음 | 공개되지 않음 | 공개되지 않음 | 의료 AI, 보안 감시, 공장 자동화 | X2X 통신 기반 SoC 간 분산 처리 아키텍처 |
| 7 | Chimera GPNPU | Quadric | 최대 108 TOPS | 약 10W | 통합 메모리 | 다양한 인터페이스 | 산업용 엣지 디바이스, 로보틱스 | 완전한 C++ 프로그래밍 가능 AI/ML 추론 솔루션 |
| 8 | Hailo-8 | Hailo | 26 TOPS | 2.5W | 통합 메모리 | PCIe Gen 3.0 x2 | 비전 AI, 스마트 카메라, IoT | 초소형 폼팩터의 고효율 AI 프로세서 |
| 9 | Inferentia 2 | Amazon | 380 TOPS (INT8) | 약 25W | 32GB HBM | NeuronLink 인터커넥트 | 클라우드 기반 AI 추론 | AWS 전용 AI 추론 칩 |
| 10 | Granite Rapids-D | Intel | 최대 288 코어 | 약 150W | 최대 384GB RAM | 다양한 인터페이스 | 5G 네트워크, 엣지 서버 | Xeon 기반의 엣지 컴퓨팅 특화 프로세서 |
🔍 요약 및 선택 가이드
- 고성능 엣지 AI 처리: NVIDIA의 Jetson Orin Nano Super와 AMD의 Ryzen AI 300 시리즈는 고성능을 요구하는 엣지 AI 애플리케이션에 적합합니다.
- 저전력 및 소형 디바이스: Hailo-8과 Qualcomm의 Snapdragon X80은 저전력 소비와 소형 폼팩터를 필요로 하는 디바이스에 이상적입니다.
- 산업 및 특수 목적: EdgeCortix의 SAKURA-II와 디퍼아이의 Tachy-BS402는 산업용 및 특수 목적의 엣지 AI 솔루션에 적합합니다.
- 클라우드 및 서버 기반: Amazon의 Inferentia 2와 Intel의 Granite Rapids-D는 클라우드 및 서버 기반의 대규모 AI 추론 작업에 최적화되어 있습니다.
각 칩의 선택은 사용자의 특정 요구 사항, 예산, 전력 소비 제한 및 애플리케이션에 따라 달라질 수 있습니다. 추가적인 정보나 특정 용도에 대한 추천이 필요하시면 알려주시기 바랍니다.

2025년 현재, 로봇용 AI 칩 분야에서 NVIDIA와 Tesla를 포함한 주요 기업들이 다양한 솔루션을 제공하고 있습니다. 아래는 로봇 및 자율 시스템에 적합한 상위 10개 AI 칩의 비교입니다:
🤖 로봇용 AI 칩 Top 10 비교 (2025년 기준)
| 순위 | 칩 이름 | 제조사 | 연산 성능 (TOPS) | 전력 소비 | 주요 특징 및 적용 분야 |
| 1 | Jetson Orin Nano Super | NVIDIA | 최대 67 TOPS | 7~15W | 소형 폼팩터, 저전력, 로봇 및 드론에 적합 |
| 2 | Jetson AGX Orin | NVIDIA | 최대 275 TOPS | 15~60W | 고성능 로봇, 자율주행 차량, 산업용 자동화에 최적화 |
| 3 | Dojo D1 | Tesla | 362 TFLOPS | 약 400W | 대규모 AI 모델 학습용, 자율주행 데이터 처리에 활용 |
| 4 | Hailo-8 | Hailo | 26 TOPS | 2.5W | 초소형 폼팩터, 비전 AI 및 스마트 카메라에 적합 |
| 5 | Edge TPU | 4 TOPS | 2W | 저전력 IoT 디바이스, 스마트 홈 애플리케이션에 활용 | |
| 6 | QCS8250 | Qualcomm | 13 TOPS | 약 10W | 5G 통신 지원, 웨어러블 및 자동차 HMI에 적합 |
| 7 | Chimera GPNPU | Quadric | 최대 108 TOPS | 약 10W | 산업용 엣지 디바이스, 로보틱스에 활용 |
| 8 | Tachy-BS402 | 디퍼아이(DeePerEye) | 공개되지 않음 | 공개되지 않음 | 의료 AI, 보안 감시, 공장 자동화에 특화된 SoC 아키텍처 |
| 9 | 240 Slim | Untether | 공개되지 않음 | 낮음 | 자율주행 차량, 농업용 로봇 등에 적합한 저전력 칩 |
| 10 | Snapdragon X80 | Qualcomm | 약 45 TOPS | 약 10W | 스마트폰, 노트북, 자동차에 활용 가능한 통합 AI 칩 |
🔍 요약 및 선택 가이드
- 소형 로봇 및 드론: NVIDIA의 Jetson Orin Nano Super와 Hailo-8은 소형 폼팩터와 저전력 소비로 드론 및 소형 로봇에 적합합니다.
- 고성능 로봇 및 자율주행: Jetson AGX Orin과 Tesla의 Dojo D1은 고성능이 요구되는 자율주행 차량 및 산업용 로봇에 활용됩니다.
- 산업용 및 특수 목적: 디퍼아이의 Tachy-BS402와 Quadric의 Chimera GPNPU는 의료 AI, 보안 감시, 공장 자동화 등 특수 목적에 최적화된 솔루션을 제공합니다.
- 저전력 IoT 디바이스: Google의 Edge TPU와 Qualcomm의 QCS8250은 저전력 소비로 스마트 홈 및 IoT 디바이스에 적합합니다.Promwad
각 칩의 선택은 사용자의 특정 요구 사항, 예산, 전력 소비 제한 및 애플리케이션에 따라 달라질 수 있습니다. 추가적인 정보나 특정 용도에 대한 추천이 필요하시면 알려주시기 바랍니다.

📊 주요 5G-AI 통합 칩셋 비교
| 칩셋 이름 | 제조사 | AI 성능 (TOPS) | 5G 지원 범위 | AI 통합 특징 및 용도 |
| Snapdragon X80 | Qualcomm | 미공개 | Sub-6GHz 및 mmWave | AI 기반 빔포밍, 채널 상태 예측, 안테나 튜닝 등으로 5G 성능 최적화 |
| QCS8250 | Qualcomm | 미공개 | Sub-6GHz 및 mmWave | Adreno 650 GPU 및 Hexagon DSP를 통한 AI 처리, IoT 및 카메라 애플리케이션에 최적화 |
| Dimensity 9300 | MediaTek | 미공개 | Sub-6GHz 및 mmWave | APU 790을 통한 고성능 AI 처리, 스마트폰 및 IoT 디바이스에 적합 |
| Exynos 2400 | Samsung | 미공개 | Sub-6GHz 및 mmWave | 17K MAC NPU와 DSP를 통한 AI 처리, 고성능 모바일 애플리케이션에 활용 |
| Apple C1 | Apple | 미공개 | Sub-6GHz | Apple의 첫 자체 개발 5G 모뎀, 전력 효율성 향상 및 배터리 수명 개선 |
| OCTEON 10 Fusion | Marvell | 8 TOPS/Watt | Sub-6GHz 및 mmWave | 5nm 공정 기반, Arm Neoverse N2 CPU 및 AI/ML 가속기 통합, 5G RAN 및 vRAN에 최적화 |
🔍 요약 및 선택 가이드
- Qualcomm Snapdragon X80: AI 기반의 다양한 5G 최적화 기능을 제공하여, 고성능 모바일 디바이스에 적합합니다.
- Qualcomm QCS8250: AI 처리 능력을 갖춘 IoT 및 카메라 애플리케이션에 최적화된 칩셋입니다.
- MediaTek Dimensity 9300: 고성능 AI 처리와 5G 통신을 통합하여, 스마트폰 및 IoT 디바이스에 적합합니다.
- Samsung Exynos 2400: 고성능 AI 처리 능력과 5G 통신을 제공하여, 프리미엄 모바일 디바이스에 활용됩니다.
- Apple C1: Apple의 자체 개발 5G 모뎀으로, 전력 효율성과 배터리 수명을 개선하여 iPhone 16E에 탑재되었습니다.
- Marvell OCTEON 10 Fusion: 5nm 공정 기반의 고성능 AI/ML 가속기와 5G 통신 기능을 통합하여, 5G RAN 및 vRAN 인프라에 최적화된 솔루션입니다.marvell.com
각 칩셋은 특정 용도와 요구 사항에 따라 선택이 달라질 수 있습니다. 추가적인 정보나 특정 용도에 대한 추천이 필요하시면 알려주시기 바랍니다.
2025년 현재, 5G 네트워크의 핵심 구성 요소인 DU(Distributed Unit), CU(Centralized Unit), UPF(User Plane Function) 및 AI 처리를 모두 지원하는 칩셋은 매우 제한적입니다. 이러한 통합 기능을 제공하는 칩셋은 주로 네트워크 인프라 장비에 사용되며, 고성능과 저전력 소비를 동시에 요구합니다.
📡 5G DU/CU/UPF 및 AI 통합 지원 칩셋
| 칩셋 이름 | 제조사 | 5G 기능 지원 범위 | AI 처리 지원 | 주요 특징 및 용도 |
| OCTEON 10 Fusion | Marvell | DU, CU, UPF | 지원 | 5nm 공정 기반, Arm Neoverse N2 CPU 및 AI/ML 가속기 통합, 5G RAN 및 vRAN에 최적화 |
| NXP Layerscape Access | NXP | DU, CU | 제한적 지원 | 통합형 SoC 솔루션으로, 5G 액세스 네트워크에 최적화되어 있으며, 일부 AI 기능 지원 |
| Intel Xeon D-2700 | Intel | DU, CU, UPF | 지원 | 고성능 서버급 프로세서로, 네트워크 기능 가상화(NFV) 및 AI 워크로드에 적합 |
| Qualcomm FSM100xx | Qualcomm | DU, CU | 제한적 지원 | 소형 셀 및 분산형 네트워크에 최적화된 칩셋으로, 일부 AI 기능 지원 |
🔍 요약 및 선택 가이드
- Marvell OCTEON 10 Fusion: 5G RAN 및 vRAN 인프라에 최적화된 솔루션으로, DU, CU, UPF 및 AI 처리를 모두 지원합니다.
- NXP Layerscape Access: 5G 액세스 네트워크에 적합한 통합형 SoC로, DU 및 CU 기능을 지원하며, 일부 AI 기능도 제공합니다.
- Intel Xeon D-2700: 고성능 서버급 프로세서로, DU, CU, UPF 및 AI 워크로드를 처리할 수 있어, 네트워크 기능 가상화(NFV)에 적합합니다.
- Qualcomm FSM100xx: 소형 셀 및 분산형 네트워크에 최적화된 칩셋으로, DU 및 CU 기능을 지원하며, 일부 AI 기능도 제공합니다.
각 칩셋은 특정 네트워크 아키텍처와 요구 사항에 따라 선택이 달라질 수 있습니다. 추가적인 정보나 특정 용도에 대한 추천이 필요하시면 알려주시기 바랍니다.
📊 5G 및 AI 칩셋 제조업체 비교
| 제조사 | 주요 제품 및 기술 | 특징 및 용도 |
| Broadcom | 3.5D XDSiP 기술, 맞춤형 AI 칩 | 대규모 클라우드 제공업체를 위한 맞춤형 AI 칩 개발, 고성능 및 고대역폭 지원 |
| Intel | Xeon D-2700, Habana Gaudi, Tofino 스위치 | 데이터 센터 및 네트워크 인프라에 최적화된 고성능 AI 및 네트워킹 솔루션 제공 |
| AMD | Versal ACAP (Xilinx 인수 후) | FPGA와 AI 가속기를 통합한 유연한 컴퓨팅 플랫폼으로 5G 및 AI 워크로드에 적합 |
| NVIDIA | BlueField DPU, Grace Hopper 슈퍼칩 | AI 및 고성능 컴퓨팅(HPC)에 최적화된 솔루션으로, 데이터 센터 및 네트워크 가속에 활용 |
| Qualcomm | FSM100xx, Snapdragon X80 | 5G 모뎀과 AI 기능을 통합한 칩셋으로, 모바일 및 IoT 디바이스에 적합 |
| MediaTek | Dimensity 시리즈 | 중급 및 고급 스마트폰을 위한 5G 및 AI 통합 칩셋 제공 |
| Samsung | Exynos 시리즈 | 자체 개발한 5G 모뎀과 AI 가속기를 통합한 칩셋으로, 모바일 디바이스에 활용 |
| EdgeQ | Base Station-on-Chip | 5G 및 AI 기능을 통합한 SoC로, 소형 셀 및 엣지 디바이스에 최적화 |
| NXP | Layerscape Access 시리즈 | 5G 액세스 네트워크 및 IoT 애플리케이션을 위한 통합형 SoC 솔루션 제공 |
| Cerebras | Wafer Scale Engine (WSE) | 대규모 AI 모델 학습을 위한 세계 최대 규모의 칩으로, HPC 및 AI 연구에 활용 |
🔍 요약 및 선택 가이드
- 대규모 클라우드 및 데이터 센터용: Broadcom, Intel, NVIDIA, AMD는 고성능과 확장성을 요구하는 데이터 센터 및 클라우드 인프라에 최적화된 솔루션을 제공합니다.
- 모바일 및 IoT 디바이스용: Qualcomm, MediaTek, Samsung은 5G 및 AI 기능을 통합한 칩셋으로 모바일 및 IoT 디바이스에 적합합니다.
- 엣지 컴퓨팅 및 소형 셀용: EdgeQ, NXP는 엣지 디바이스 및 소형 셀 네트워크에 최적화된 통합형 SoC 솔루션을 제공합니다.
- AI 연구 및 HPC용: Cerebras는 대규모 AI 모델 학습과 HPC 애플리케이션을 위한 고성능 칩을 제공합니다.VKTR.com+2Business Insider+2CRN+2
각 제조사는 특정 용도와 시장에 맞는 솔루션을 제공하므로, 필요에 따라 적합한 칩셋을 선택하는 것이 중요합니다.
1. NVIDIA의 Jetson Orin Nano Super

NVIDIA의 Jetson Orin Nano Super는 소형 폼팩터에서 고성능 AI 처리를 가능하게 하는 개발 키트로, 로봇, 드론, 자율주행 시스템, 스마트 카메라 등 엣지 AI 애플리케이션에 최적화되어 있습니다.
🔧 주요 사양
- GPU: NVIDIA Ampere 아키텍처 기반, 1,024 CUDA 코어 및 32 텐서 코어
- CPU: 6코어 Arm Cortex-A78AE v8.2 64비트, 최대 1.7GHz
- 메모리: 8GB 128비트 LPDDR5, 최대 102GB/s 대역폭
- AI 성능: 최대 67 TOPS (INT8 기준)
- 전력 소비: 7W ~ 25W, MAXN SUPER 모드 지원
- 저장장치: microSD 카드 슬롯, M.2 NVMe SSD 지원
- 입출력 포트:
- USB 3.2 Gen2 Type-A 포트 4개
- USB Type-C 포트 1개
- Gigabit Ethernet 포트
- DisplayPort 출력
- MIPI CSI-2 카메라 커넥터 2개
- 40핀 확장 헤더
- M.2 Key M 및 Key E 슬롯SparkFun+6NVIDIA+6tiendatec.es+6위키백과+9위키백과+9RS Components+9The Verge+4StorageReview.com+4NVIDIA+4NVIDIA+6위키백과+6NVIDIA+6NVIDIA+2Stereolabs+2NVIDIA+2Electronics-Lab.com+5siliconhighwaydirect.com+5SparkFun+5NVIDIA Developer+1siliconhighwaydirect.com+1
🚀 성능 향상
JetPack 6.2 소프트웨어 업데이트를 통해 기존 Jetson Orin Nano 개발 키트의 성능을 향상시킬 수 있습니다. 이 업데이트는 GPU, 메모리, CPU 클럭을 증가시켜 AI 성능을 40 TOPS에서 67 TOPS로, 메모리 대역폭을 68GB/s에서 102GB/s로 향상시킵니다. Stereolabs+1NVIDIA+1Stereolabs+3The Verge+3NVIDIA+3
💡 활용 분야
- 로봇 및 드론: 실시간 AI 추론과 센서 융합 처리에 적합
- 스마트 시티: 교통 모니터링, 공공 안전, 인프라 감시에 활용
- 산업 자동화: 비전 기반 품질 검사 및 예측 유지보수에 활용
- 헬스케어: 의료 영상 분석 및 환자 모니터링 시스템에 적용
💰 가격 및 구매 정보
Jetson Orin Nano Super 개발 키트는 NVIDIA 공식 유통사를 통해 약 $249에 구매할 수 있습니다. 기존 Orin Nano 개발 키트 사용자도 JetPack 6.2 업데이트를 통해 동일한 성능 향상을 경험할 수 있습니다.WSJ+5The Verge+5NVIDIA+5Stereolabs
2. Snapdragon X80

Qualcomm의 Snapdragon X80 5G Modem-RF System은 2024년 MWC에서 공개된 7세대 5G 모뎀-안테나 통합 솔루션으로, 5G Advanced(3GPP Release 18) 지원과 AI 기반 성능 향상을 특징으로 합니다.CNX Software - Embedded Systems News+2The Futurum Group+2docs.qualcomm.com+2
📶 주요 사양
- 최대 다운로드 속도: 10 Gbps
- 최대 업로드 속도: 3.5 Gbps
- 지원 주파수: 전 세계 5G 밴드(0.6~41 GHz)
- 캐리어 어그리게이션: 서브-6GHz에서 6개 캐리어 어그리게이션 지원
- 안테나 구성: 스마트폰용 6Rx 안테나 아키텍처
- 위성 통신: NB-NTN 위성 통신 완전 통합91Mobiles+4퀄컴+4FoneArena+491Mobiles+5CNX Software - Embedded Systems News+5The Futurum Group+5Android Authorityskylo.tech+8The Futurum Group+8CNX Software - Embedded Systems News+8
🧠 AI 기반 성능 향상
Snapdragon X80은 전용 텐서 가속기를 탑재한 Qualcomm 5G AI Processor Gen 2를 통해 다음과 같은 기능을 제공합니다:CNX Software - Embedded Systems News+2docs.qualcomm.com+2The Futurum Group+2
- AI 기반 mmWave 빔 관리로 커버리지 및 속도 향상
- AI 기반 GNSS 위치 정확도 개선
- 전력 효율성 및 지연 시간 최적화
- Qualcomm Smart Network Selection Gen 3를 통한 네트워크 선택 최적화docs.qualcomm.com+1CNX Software - Embedded Systems News+1The Futurum Group+2CNX Software - Embedded Systems News+2docs.qualcomm.com+2
🌐 활용 분야
Snapdragon X80은 스마트폰, 모바일 브로드밴드, 자동차, 컴퓨팅, XR, 산업용 IoT, 고정 무선 액세스(FWA), 5G 프라이빗 네트워크 등 다양한 분야에 적용 가능합니다.docs.qualcomm.com+1The Futurum Group+1
📅 출시 일정
Snapdragon X80은 2024년 하반기에 상용화될 예정이며, Snapdragon 8 Gen 4 SoC와 함께 탑재될 것으로 예상됩니다.91Mobiles+1FoneArena+1
3. AMD의 Ryzen AI 300 시리즈

AMD의 Ryzen AI 300 시리즈는 2024년 6월 컴퓨텍스에서 발표된 차세대 모바일 프로세서 라인업으로, AI 연산에 최적화된 고성능 NPU와 최신 CPU 및 GPU 아키텍처를 통합한 것이 특징입니다.
🔍 주요 특징
- CPU 아키텍처: 최신 Zen 5 및 고밀도 Zen 5c 코어를 조합하여 최대 12코어(24스레드) 구성
- NPU (AI 엔진): XDNA 2 기반 3세대 Ryzen AI 엔진 탑재로 최대 50 TOPS의 AI 연산 성능 제공
- GPU: RDNA 3.5 아키텍처 기반 Radeon 800M 시리즈 통합 그래픽으로 최대 16개의 컴퓨트 유닛(CU) 지원
- 메모리 지원: LPDDR5X-8000 또는 DDR5-5600 메모리 지원
- TDP 범위: 15W에서 54W까지 조정 가능하여 다양한 노트북 설계에 유연하게 대응위키백과+8LaptopMedia+8위키백과+8위키백과+3Investor's Business Daily+3위키백과+3위키백과+3위키백과+3위키백과+3
📊 대표 모델 비교
| 모델명 | CPU 구성 | GPU (CU 수) | NPU 성능 (TOPS) | L3 캐시 | 최대 부스트 클럭 | TDP 범위 |
| Ryzen AI 9 HX 370 | 4x Zen 5 + 8x Zen 5c (12코어 24스레드) | Radeon 890M (16 CU) | 50 | 24MB | 5.1GHz | 15–54W |
| Ryzen AI 9 365 | 4x Zen 5 + 6x Zen 5c (10코어 20스레드) | Radeon 880M (12 CU) | 50 | 24MB | 5.0GHz | 15–54W |
| Ryzen AI 7 350 | 4x Zen 5 + 4x Zen 5c (8코어 16스레드) | Radeon 870M (8 CU) | 50 | 16MB | 5.0GHz | 15–54W |
| Ryzen AI 5 340 | 4x Zen 5 + 2x Zen 5c (6코어 12스레드) | Radeon 860M (6 CU) | 50 | 16MB | 4.8GHz | 15–54W |
💡 활용 분야
- AI 기반 애플리케이션: Copilot+ PC와 같은 AI 지원 기능을 활용하는 업무 환경
- 고성능 모바일 컴퓨팅: 얇고 가벼운 노트북에서의 고성능 연산 및 멀티태스킹
- 그래픽 및 멀티미디어 작업: 통합 GPU를 활용한 영상 편집, 3D 렌더링 등The Verge+3XenoSpectrum+3LaptopMedia+3
🛠️ 제품 예시
- Framework Laptop 13 (Ryzen AI 300 시리즈 탑재): 모듈형 설계를 갖춘 노트북으로, Ryzen AI 9 HX 370 프로세서를 탑재하여 높은 성능과 확장성을 제공합니다. 위키백과+4The Verge+4LaptopMedia+4
4. Google의 Edge TPU 시리즈

Google의 Edge TPU 시리즈는 엣지 디바이스에서 효율적인 AI 추론을 가능하게 하는 저전력 ASIC(특정 용도용 집적 회로)입니다. 이러한 칩은 TensorFlow Lite 모델을 기반으로 하며, Coral 브랜드를 통해 다양한 형태로 제공됩니다.Coral+4Nordcloud+4위키백과+4
🔍 주요 특징
- 연산 성능: Edge TPU는 최대 4 TOPS(초당 4조 연산)의 성능을 제공하며, 2W의 전력으로 동작합니다 .위키백과+1Murata+1
- 지원 프레임워크: TensorFlow Lite를 기반으로 하며, 8비트 정수 연산에 최적화되어 있습니다.
- 지원 플랫폼: Debian 기반의 Linux 시스템에서 지원되며, 일부 제품은 macOS 및 Windows 10에서도 사용 가능합니다 .Coral
🧩 제품 라인업
| 제품명 | 형태 | 특징 및 용도 |
| USB Accelerator | USB 액세서리 | 기존 시스템에 USB로 연결하여 AI 추론 기능 추가 . |
| Dev Board | 단일 보드 컴퓨터 | Edge TPU가 탑재된 SoM(System-on-Module)을 포함한 개발 보드 . |
| Dev Board Mini | 소형 개발 보드 | Coral Accelerator Module과 MediaTek SoC를 통합한 소형 보드 . |
| System-on-Module (SoM) | 모듈형 보드 | Edge TPU와 NXP i.MX 8M SoC를 통합한 모듈 . |
| M.2 Accelerator | M.2 카드 | M.2 슬롯을 통해 시스템에 통합 가능한 AI 가속기 . |
| PCIe Accelerator | PCIe 카드 | PCIe 슬롯을 통해 시스템에 통합 가능한 AI 가속기 . |
📊 성능 비교
Edge TPU는 8비트 정수 연산에 최적화되어 있으며, 다양한 모델에서 높은 추론 속도를 제공합니다. 예를 들어, MobileNet V2 모델을 사용할 경우, Edge TPU는 CPU 대비 최대 10배 이상의 속도 향상을 보여줍니다 .
💡 활용 분야
- 스마트 카메라: 실시간 객체 감지 및 얼굴 인식유튜브
- 산업 자동화: 불량품 검출 및 품질 관리
- 헬스케어: 환자 모니터링 및 이상 징후 감지ML6team+4위키백과+4Coral+4
- 스마트 홈: 음성 인식 및 사용자 행동 분석
Edge TPU 시리즈는 저전력으로 고성능 AI 추론을 필요로 하는 다양한 엣지 컴퓨팅 애플리케이션에 적합합니다. 특히, 실시간 처리와 프라이버시 보호가 중요한 분야에서 유용하게 활용될 수 있습니다.
추가적인 정보나 특정 용도에 대한 추천이 필요하시면 알려주시기 바랍니다.
5. EdgeCortix의 SAKURA-II

EdgeCortix의 SAKURA-II는 에너지 효율성과 고성능을 겸비한 엣지 AI 추론 가속기로, 특히 생성형 AI(Generative AI) 및 대규모 언어 모델(LLM)과 같은 복잡한 AI 워크로드를 엣지 환경에서 효과적으로 처리하도록 설계되었습니다.
🔧 주요 사양 및 특징
- 연산 성능:
- 최대 60 TOPS (INT8)
- 최대 30 TFLOPS (BF16)
- 혼합 정밀도(Mixed Precision) 지원EdgeCortix+13EdgeCortix+13Hardware libre+13EdgeCortix+7EdgeCortix+7Silicon Hub+7
- 메모리:
- 온보드 DRAM 최대 32GB (LPDDR4)
- 메모리 대역폭 최대 68 GB/sSilicon Hub+6EdgeCortix+6EdgeCortix+6
- 전력 소비:
- 단일 SAKURA-II: 약 10W
- 듀얼 SAKURA-II: 약 20WEdgeCortix+2Hardware libre+2EdgeCortix+2
- 온칩 SRAM: 20MB
- 온도 범위: -20°C ~ 85°CEdgeCortix+1EdgeCortix+1
- 지원 모델: Llama 2/3, Stable Diffusion, Whisper, Vision Transformer 등전자제품.com+4Edge Industry Review+4EdgeCortix+4
- 소프트웨어 프레임워크: MERA 컴파일러 및 런타임, PyTorch, TensorFlow Lite, ONNX 지원BittWare+3EdgeCortix+3비즈니스와이어+3
🧩 제품 라인업
1. M.2 모듈
- 사양:
- 형태: M.2 Key M 2280 (22mm x 80mm)
- 인터페이스: PCIe Gen 3.0 x4
- DRAM: 8GB 또는 16GB LPDDR4
- 전력 소비: 약 10WHubSpot+5EdgeCortix+5EdgeCortix+5EdgeCortix+4Hardware libre+4CNX Software - Embedded Systems News+4CNX Software - Embedded Systems News
- 가격:
- 8GB 모델: $249
- 16GB 모델: $299CNX Software - Embedded Systems NewsHardware libre+1CNX Software - Embedded Systems News+1
- 특징: 공간 제약이 있는 설계에 적합하며, 생성형 AI 및 메모리 집약적인 AI 애플리케이션에 최적화되어 있습니다.
2. PCIe 카드
- 사양:
- 형태: 로우 프로파일, 싱글 슬롯
- 인터페이스: PCIe Gen 3.0 x8 (단일), PCIe Gen 3.0 x8/x8 (듀얼)
- DRAM: 단일 16GB, 듀얼 32GB LPDDR4
- 전력 소비: 단일 약 10W, 듀얼 약 20WEdgeCortix+1EdgeCortix+1CNX Software - Embedded Systems News
- 가격:
- 단일 SAKURA-II: $429
- 듀얼 SAKURA-II: $749비즈니스와이어+4Hardware libre+4CNX Software - Embedded Systems News+4
- 특징: 대규모 AI 추론 작업에 적합하며, 높은 AI 처리 능력을 필요로 하는 설계에 이상적입니다.
💡 활용 분야
- 산업 자동화: 실시간 비전 분석 및 품질 검사
- 스마트 시티: 교통 모니터링 및 공공 안전 시스템
- 로보틱스 및 드론: 실시간 경로 계획 및 객체 인식
- 헬스케어: 의료 영상 분석 및 환자 모니터링
- 통신: 5G 및 프라이빗 네트워크에서의 AI 기반 데이터 처리Hardware libre+2CNX Software - Embedded Systems News+2EdgeCortix+2EdgeCortix+1Hardware libre+1
SAKURA-II는 엣지 환경에서의 고성능 AI 추론을 위해 설계된 솔루션으로, 다양한 산업 분야에서의 적용이 가능합니다. 특히, 에너지 효율성과 성능을 동시에 요구하는 애플리케이션에 적합합니다.
6. Tachy-BS402

Tachy-BS402는 한국의 AI 반도체 설계 기업 **디퍼아이(Deeper-I)**가 자체 개발한 엣지(Edge) AI 추론용 SoC(System-on-Chip)입니다. 이 칩은 저전력 고성능 AI 연산을 목표로 설계되었으며, 특히 영상 및 음성 기반의 실시간 AI 애플리케이션에 최적화되어 있습니다.미래를 보는 창 - 전자신문+8Deeper-I+8Edge AI and Vision Alliance+8
🔍 주요 특징
- X2X 칩간 통신 기술: 디퍼아이가 자체 개발한 X2X 기술은 SoC 간의 효율적인 통신을 가능하게 하여, 딥러닝 연산을 분산 처리하고 음성 및 영상 데이터를 동시에 처리할 수 있도록 지원합니다. 다음+6톱데일리+6미래를 보는 창 - 전자신문+6
- 고효율 AI 추론 성능: Tachy-BS402는 GPU 기반의 범용 AI 칩보다 효율적으로 학습 데이터를 활용할 수 있으며, 다양한 AI 애플리케이션에 쉽게 적용할 수 있는 환경을 제공합니다. 톱데일리+2톱데일리+2미래를 보는 창 - 전자신문+2
- 저전력 설계: 약 2W의 전력 소비로 고성능 AI 추론을 가능하게 하여, 전력 효율성이 중요한 엣지 디바이스에 적합합니다.
🧩 적용 사례
- 의료 분야: 디퍼아이는 시너지에이아이와 협력하여 부정맥 예측진단 솔루션 '맥케이(Mac'AI)'에 Tachy-BS402를 탑재하였습니다. 이 솔루션은 초소형 USB형 반도체 위에서 딥러닝 학습된 AI 모델을 구동하며, 92.7%의 예측 정확도를 보였습니다. Deeper-I+4뉴스핌+4톱데일리+4
- 산업 자동화 및 보안: Tachy-BS402는 군 야간감시장비, 공장 자동화, 스마트 시티 등 다양한 분야에서의 적용이 가능하며, 디퍼아이는 이러한 분야로의 확장을 계획하고 있습니다. 톱데일리+1미래를 보는 창 - 전자신문+1
🏭 생산 및 파트너십
디퍼아이는 TSMC를 통해 Tachy-BS402의 양산을 진행하였으며, 한국의 TSMC 디자인 하우스인 에이직랜드와 협력하여 백엔드 설계를 완료하였습니다. 네이트 뉴스+6톱데일리+6톱데일리+6
📸 제품 이미지
디퍼아이가 양산한 엣지형 AI 반도체 Tachy-BS402를 적용한 SoC 모듈의 이미지입니다:네이버 블로그+7미래를 보는 창 - 전자신문+7미래를 보는 창 - 전자신문+7
Tachy-BS402는 저전력 고성능 AI 추론을 필요로 하는 다양한 엣지 컴퓨팅 애플리케이션에 적합한 솔루션으로, 디퍼아이는 이를 기반으로 다양한 산업 분야에서의 적용을 확대해 나가고 있습니다.뉴스핌+7톱데일리+7미래를 보는 창 - 전자신문+7
7. Chimera GPNPU
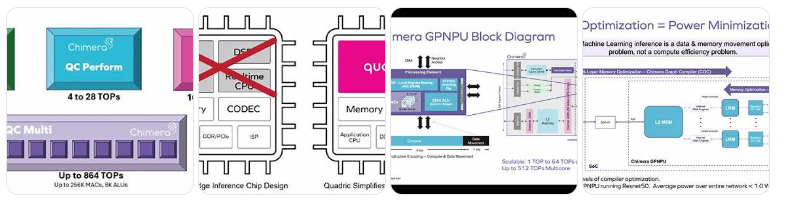
Chimera GPNPU는 미국의 AI 반도체 IP 기업 Quadric이 개발한 범용 신경처리장치(General-Purpose Neural Processing Unit)로, 머신러닝(ML) 추론과 디지털 신호 처리(DSP)를 단일 코어에서 통합 처리할 수 있도록 설계되었습니다. 2024년에 발표된 3세대 Chimera QC 시리즈는 자동차, 엣지 AI, 생성형 AI 등 다양한 분야에 최적화된 성능과 유연성을 제공합니다.세미위키+3비즈니스와이어+3세미위키+3세미위키
🔧 주요 사양 및 아키텍처
- 단일 코어 성능:
- QC Nano: 최대 7 TOPS (INT8 기준)
- QC Perform: 최대 28 TOPS
- QC Ultra: 최대 108 TOPS세미위키+1jonpeddie.com+1
- 멀티코어 클러스터 (QC-M):
- 2, 4, 8개의 코어를 조합하여 최대 864 TOPS까지 확장 가능
- 고속 AXI 인터페이스 및 스트리밍 가중치 공유 기능 지원세미위키+1jonpeddie.com+1
- 데이터 정밀도 및 지원:
- INT8, FP16, 4비트 가중치 지원
- 최대 1024비트 AXI 인터페이스로 대규모 모델 처리에 최적화
- 아키텍처 특징:
- NPU, DSP, 실시간 CPU 기능을 단일 코어에 통합
- C++ 기반의 Chimera Compute Library (CCL) 및 SDK 제공
- ResNet, Vision Transformer, Llama 2/3 등 최신 AI 모델 지원 CNX Software - Embedded Systems News
🚗 자동차 및 안전 기능
- Safety Enhanced 버전:
- ASIL-B 및 ASIL-D 수준의 기능 안전을 지원하여 자동차용 SoC에 적합
- ISO 26262 인증을 위한 FMEA 및 DIA 보고서 제공세미위키+1jonpeddie.com+1
- 적용 사례:
- 레벨 4 자율주행 시스템에서 멀티 카메라 스트림을 병렬로 처리하는 ADAS 중앙 처리 장치
- 3nm 공정 기반 칩렛 설계 시, 400 TOPS 이상의 성능을 $10 미만의 다이 비용으로 구현 가능 세미위키+1jonpeddie.com+1
🧠 생성형 AI 및 LLM 최적화
- 4비트 가중치 지원:
- 대규모 언어 모델(LLM)에서 가중치 스트리밍 대역폭을 절감하여 효율적인 추론 가능
- 유연한 MAC 구성:
- 8, 16, 32개의 INT8 MAC을 선택적으로 구성하여 다양한 워크로드에 최적화세미위키+1jonpeddie.com+1
- 프로그래머블 아키텍처:
- 고정 기능 NPU와 달리, 새로운 연산자나 모델 구조에 유연하게 대응 가능
🧩 적용 분야
- 엣지 AI: 로봇, 드론, 스마트 카메라 등에서의 실시간 AI 추론
- 자동차: ADAS, 자율주행, 차량 내 인포테인먼트 시스템
- 산업 자동화: 비전 검사, 음성 인식, 제어 시스템 등
- 사무 자동화: Kyocera와의 협업을 통해 문서 처리 및 인쇄 장비에 AI 기능 통합 비즈니스와이어
📸 대표 이미지
Chimera GPNPU는 고성능 AI 추론과 DSP 기능을 단일 코어에서 통합하여, 다양한 산업 분야에서의 AI 적용을 간소화하고 효율성을 극대화합니다. 특히, 자동차 및 생성형 AI 분야에서의 활용 가능성이 높으며, 향후 다양한 제품에 적용될 것으로 기대됩니다.
8. Hailo-8 , 이스라엘의 AI 반도체 기업 Hailo Technologies 가 개발

Hailo-8는 이스라엘의 AI 반도체 기업 Hailo Technologies가 개발한 엣지 AI 추론용 프로세서로, 높은 연산 성능과 저전력 소비를 특징으로 합니다. 이 칩은 다양한 엣지 디바이스에서 실시간 AI 추론을 가능하게 하며, 특히 영상 분석, 자율주행, 산업 자동화 등 다양한 분야에 적용되고 있습니다.
🔍 주요 사양 및 특징
- 연산 성능: 최대 26 TOPS (Tera Operations Per Second)Hailo+7Hailo+7Waveshare+7
- 전력 소비: 일반적으로 2.5W, 최대 8.65Wlannerinc.com+7Waveshare+7웨이브쉐어+7
- 인터페이스: PCIe Gen 3.0 (2-lane 또는 4-lane)Hailo+4up-board.org+4kagafeiamerica.com+4
- 폼 팩터: M.2 (Key M, B+M, A+E), mPCIe, PCIe 카드 등 다양한 형태로 제공up-board.org+3Hailo+3kagafeiamerica.com+3
- 지원 프레임워크: TensorFlow, TensorFlow Lite, Keras, PyTorch, ONNX 등Hailo+6up-board.org+6Hailo+6
- 지원 OS: Linux, Windows웨이브쉐어+2kagafeiamerica.com+2Hailo+2
- 작동 온도 범위: -40°C ~ 85°C (산업용 등급)
- 데이터플로우 아키텍처: 신경망의 구조적 특성을 활용한 구조 중심의 데이터플로우 아키텍처로, 높은 효율성과 확장성을 제공합니다.Hailo
🧩 제품 라인업
| 제품명 | 형태 | 특징 및 용도 |
| Hailo-8 M.2 모듈 | M.2 모듈 | 다양한 엣지 디바이스에 통합 가능하며, 최대 26 TOPS의 성능 제공WaveshareHailo+5Hailo+5CNX Software - Embedded Systems News+5 |
| Hailo-8R mPCIe 모듈 | mPCIe 모듈 | 소형 폼 팩터로, 공간 제약이 있는 시스템에 적합
| Hailo-8 Century PCIe 카드| PCIe 카드 | 고성능 엣지 서버 및 산업용 시스템에 적합한 솔루션
| Hailo-8L | M.2 모듈 | 최대 13 TOPS의 성능을 제공하는 엔트리 레벨 AI 가속기
💡 활용 분야
- 자동차: ADAS 및 자율주행 시스템에서의 실시간 객체 감지 및 추적
- 산업 자동화: 비전 검사, 이상 탐지, 로봇 제어 등
- 스마트 시티: 교통 모니터링, 보안 감시, 공공 안전 시스템
- 소매 및 리테일: 고객 행동 분석, 재고 관리, POS 시스템
- 의료: 의료 영상 분석, 환자 모니터링 시스템
📸 제품 이미지
Hailo-8은 높은 연산 성능과 에너지 효율성을 바탕으로 다양한 엣지 AI 애플리케이션에 적합한 솔루션을 제공합니다. 특히, 실시간 처리와 저전력 소비가 중요한 분야에서 탁월한 성능을 발휘합니다.
9. AWS Inferentia 2는 Amazon Web Services(AWS)가 개발한 2세대 머신러닝 추론 전용 칩

AWS Inferentia 2는 Amazon Web Services(AWS)가 개발한 2세대 머신러닝 추론 전용 칩으로, 대규모 언어 모델(LLM)과 생성형 AI 모델의 효율적인 추론을 위해 설계되었습니다. 이 칩은 EC2 Inf2 인스턴스를 통해 제공되며, 고성능과 에너지 효율성을 동시에 제공합니다.Amazon Web Services, Inc.+10Amazon Web Services, Inc.+10Hugging Face+10
🔧 주요 사양 및 아키텍처
Inferentia 2 칩 구성
- NeuronCore-v2: 각 칩에는 2개의 NeuronCore-v2가 탑재되어 있으며, 다음과 같은 성능을 제공합니다:
- INT8: 380 TOPS
- FP16/BF16/cFP8/TF32: 190 TFLOPS
- FP32: 47.5 TFLOPS Amazon Web Services, Inc.+4awsdocs-neuron.readthedocs-hosted.com+4awsdocs-neuron.readthedocs-hosted.com+4Amazon Web Services, Inc.+2awsdocs-neuron.readthedocs-hosted.com+2awsdocs-neuron.readthedocs-hosted.com+2Amazon Web Services, Inc.+4Amazon Web Services, Inc.+4awsdocs-neuron.readthedocs-hosted.com+4
- 메모리: 32GB의 고대역폭 메모리(HBM) 탑재, 대역폭 820 GB/sAmazon Web Services, Inc.+6Amazon Web Services, Inc.+6awsdocs-neuron.readthedocs-hosted.com+6
- 데이터 전송: 1 TB/s의 DMA 대역폭, 실시간 압축/해제 지원Amazon Web Services, Inc.+3awsdocs-neuron.readthedocs-hosted.com+3awsdocs-neuron.readthedocs-hosted.com+3
- NeuronLink-v2: 칩 간 고속 통신을 위한 인터커넥트, 192 GB/s의 대역폭 제공awsdocs-neuron.readthedocs-hosted.com
- 프로그램 가능성: 동적 입력 형태 및 제어 흐름 지원, C++로 작성된 사용자 정의 연산자 지원
📊 EC2 Inf2 인스턴스 구성
| 인스턴스 유형 | Inferentia2 칩 수 | 가속기 메모리 | vCPU 수 | 시스템 메모리 | 네트워크 대역폭 |
| inf2.xlarge | 1 | 32 GB | 4 | 16 GB | 최대 15 Gbps |
| inf2.8xlarge | 1 | 32 GB | 32 | 128 GB | 최대 25 Gbps |
| inf2.24xlarge | 6 | 192 GB | 96 | 384 GB | 50 Gbps |
| inf2.48xlarge | 12 | 384 GB | 192 | 768 GB | 100 Gbps |
🚀 성능 및 활용 사례
- 성능 향상: 이전 세대인 Inferentia 1 대비 최대 4배의 처리량 증가 및 최대 10배의 지연 시간 감소 Amazon Web Services, Inc.
- 에너지 효율성: 동급 EC2 인스턴스 대비 최대 50% 향상된 성능/전력 효율성 제공Amazon Web Services, Inc.+1Amazon Web Services, Inc.+1
- 지원 데이터 타입: FP32, TF32, BF16, FP16, UINT8, cFP8 등 다양한 데이터 타입 지원awsdocs-neuron.readthedocs-hosted.com+6Amazon Web Services, Inc.+6Amazon Web Services, Inc.+6
- 적용 분야:
- 대규모 언어 모델 추론: GPT-3, Llama 2/3 등
- 생성형 AI 애플리케이션: Stable Diffusion, Vision Transformers 등
- 실시간 서비스: 챗봇, 음성 인식, 이미지 생성 등CostCalc+3Amazon Web Services, Inc.+3Medium+3
🧰 개발 도구 및 프레임워크
- AWS Neuron SDK: PyTorch, TensorFlow 등과 통합되어 모델 컴파일, 디버깅, 최적화 지원
- transformers-neuronx: GPT2, GPT-J, OPT 등의 모델을 위한 추론 최적화 라이브러리 Amazon Web Services, Inc.
- DJLServing: 고성능 모델 서빙 솔루션으로, 대규모 언어 모델의 효율적인 배포 지원
AWS Inferentia 2는 대규모 AI 모델의 효율적인 추론을 위한 강력한 솔루션으로, 고성능과 에너지 효율성을 동시에 제공합니다. 특히, 대규모 언어 모델 및 생성형 AI 애플리케이션에 적합하며, AWS의 다양한 인스턴스 옵션과 도구를 통해 손쉽게 활용할 수 있습니다.
10. Intel Xeon 6 SoC "Granite Rapids-D

**Intel Xeon 6 SoC "Granite Rapids-D"**는 2025년에 출시된 엣지 컴퓨팅 및 통신 인프라를 위한 고성능 시스템 온 칩(SoC)입니다. 이전 세대인 Ice Lake-D의 후속 제품으로, 향상된 연산 성능, 통합 가속기, 고속 네트워킹 기능을 제공합니다.ServeTheHome
🔧 주요 사양
- 코어 구성: 최대 72개의 P-코어(Redwood Cove 아키텍처)
- 메모리 지원: DDR5-6400, 최대 8채널 구성
- PCIe 및 CXL: 최대 32개의 PCIe Gen5 레인, CXL 2.0 지원
- 네트워킹: 통합 100GbE 또는 200GbE 이더넷
- 가속기:
- AMX(Advanced Matrix Extensions)
- Intel QuickAssist Technology(QAT)
- Data Streaming Accelerator(DSA)
- Dynamic Load Balancer(DLB)
- vRAN Boost
- 보안 기능: Intel SGX 및 TDX 지원
- 패키징 기술: EMIB(Embedded Multi-die Interconnect Bridge) 기반 칩렛 설계Newsroom+4Appuals+4위키백과+4Intel Documentation+2위키백과+2ServeTheHome+2Hewlett Packard Enterprise+7ServeTheHome+7ServeTheHome+7Supermicro+1ServeTheHome+1
🚀 성능 및 활용 분야
- AI 추론: AMX를 통한 향상된 AI 추론 성능
- 미디어 처리: AVC, HEVC, AV1 등의 비디오 코덱을 지원하는 미디어 트랜스코딩 가속기
- 네트워크 기능 가상화(NFV): vRAN Boost를 통한 가상화된 RAN 처리 성능 향상
- 엣지 컴퓨팅: 고온/저온 환경에서도 안정적인 작동을 위한 설계위키백과+2ServeTheHome+2ServeTheHome+2Newsroom+8ServeTheHome+8Newsroom+8
🧩 제품 구성 및 파트너십
- HPE ProLiant DL110 Gen12: Intel Xeon 6 SoC를 탑재한 1U 폼 팩터의 서버로, 통신 환경에 최적화되어 있습니다.
- Supermicro SYS-112D 시리즈: AI 엣지 컴퓨팅을 위한 고성능 서버로, 다양한 가속기와 고속 네트워킹 기능을 통합하고 있습니다.Hewlett Packard Enterprise
📊 벤치마크 및 비교
Intel Xeon 6 SoC는 이전 세대인 Xeon D-2798NT 대비 최대 2.9배의 성능 향상을 보여주며, AI 추론 및 네트워크 처리에서 뛰어난 효율성을 제공합니다.Intel Documentation+1ServeTheHome+1
Granite Rapids-D는 엣지 컴퓨팅, 5G 네트워크, AI 추론 등 다양한 분야에서 고성능과 에너지 효율성을 동시에 제공하는 솔루션으로, 향후 다양한 산업 분야에서의 활용이 기대됩니다.
11. (로봇용) NVIDIA Jetson AGX Orin

NVIDIA Jetson AGX Orin은 엣지 AI 및 로보틱스 애플리케이션을 위한 고성능 시스템 온 모듈(SOM)로, 서버급 AI 성능을 소형 폼 팩터에서 제공합니다.NVIDIA
🔧 주요 사양
| 항목 | Jetson AGX Orin 64GB | Jetson AGX Orin 32GB |
| AI 성능 | 최대 275 TOPS (INT8) | 최대 200 TOPS (INT8) |
| GPU | 2048코어 NVIDIA Ampere 아키텍처 GPU, 64 Tensor 코어 | 1792코어 NVIDIA Ampere 아키텍처 GPU, 56 Tensor 코어 |
| CPU | 12코어 Arm Cortex-A78AE v8.2 64비트 CPU | 8코어 Arm Cortex-A78AE v8.2 64비트 CPU |
| 메모리 | 64GB 256비트 LPDDR5 (204.8GB/s 대역폭) | 32GB 256비트 LPDDR5 (204.8GB/s 대역폭) |
| 스토리지 | 64GB eMMC 5.1 | 64GB eMMC 5.1 |
| 전력 소비 | 15W ~ 60W (구성 가능) | 15W ~ 50W (구성 가능) |
| 폼 팩터 | 100mm x 87mm | 100mm x 87mm |
| I/O 인터페이스 | 22x PCIe Gen4 레인, USB 3.2 Gen2, MIPI CSI-2, GPIO 등 | 22x PCIe Gen4 레인, USB 3.2 Gen2, MIPI CSI-2, GPIO 등 |
⚙️ 아키텍처 및 기능
- GPU: NVIDIA Ampere 아키텍처 기반으로, 고성능 AI 연산을 지원합니다.
- CPU: Arm Cortex-A78AE 코어를 탑재하여, 효율적인 연산 처리가 가능합니다.
- 딥러닝 가속기: 2x NVDLA v2.0 및 PVA v2.0을 포함하여, 딥러닝 및 비전 애플리케이션을 가속화합니다.
- 비디오 처리:
- 인코딩: 최대 2x 4K60, 4x 4K30, 8x 1080p60, 16x 1080p30 (H.265)
- 디코딩: 최대 1x 8K30, 3x 4K60, 7x 4K30, 11x 1080p60, 22x 1080p30 (H.265)
- 전력 관리: 15W에서 60W까지 구성 가능하여, 다양한 애플리케이션 요구 사항에 맞게 조정할 수 있습니다.Stereolabs+9Eizo Rugged+9NVIDIA Developer+9Stereolabs+3Waveshare+3server-parts.eu+3
🧠 활용 분야
- 로보틱스: 자율 주행, 물류 로봇, 드론 등에서의 실시간 AI 추론 및 센서 융합 처리
- 산업 자동화: 비전 검사, 이상 탐지, 제어 시스템 등에서의 고성능 연산
- 스마트 시티: 교통 모니터링, 보안 감시, 공공 안전 시스템 등에서의 실시간 데이터 처리
- 의료: 의료 영상 분석, 환자 모니터링 시스템 등에서의 AI 기반 진단 지원
- 자율 주행 차량: 객체 인식, 경로 계획, 센서 융합 등에서의 고성능 AI 연산
🛠️ 개발 도구 및 소프트웨어 지원
- JetPack SDK: CUDA, cuDNN, TensorRT, DeepStream, Isaac SDK 등을 포함하여, AI 및 로보틱스 애플리케이션 개발을 지원합니다.
- Jetson Linux: Ubuntu 기반의 운영 체제로, 개발자에게 친숙한 환경을 제공합니다.
- 개발 키트: Jetson AGX Orin 개발자 키트를 통해, 빠른 프로토타이핑과 테스트가 가능합니다.
Jetson AGX Orin은 엣지 AI 및 로보틱스 애플리케이션을 위한 강력한 플랫폼으로, 높은 연산 성능과 에너지 효율성을 제공합니다. 다양한 산업 분야에서의 적용이 가능하며, 개발자에게 유연한 개발 환경을 제공합니다.
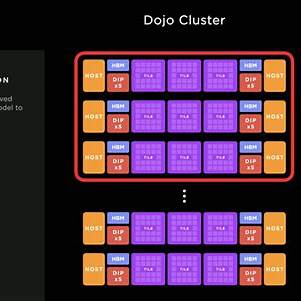
12. (로봇용) Tesla Dojo D1
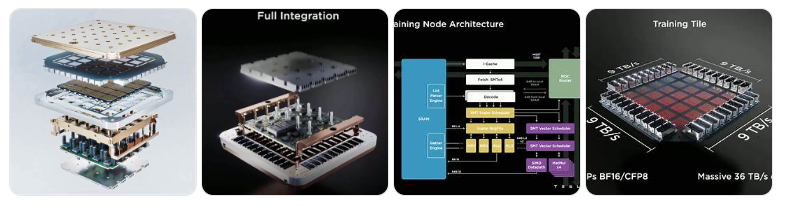
Tesla Dojo D1는 테슬라가 자율주행 AI 모델의 학습을 위해 자체 설계한 고성능 AI 학습용 칩입니다. 이 칩은 Dojo 슈퍼컴퓨터의 핵심 구성 요소로, 대규모 비디오 데이터 기반의 신경망 학습을 효율적으로 처리하도록 설계되었습니다.
🔧 주요 사양
- 제조 공정: TSMC 7nm 공정
- 트랜지스터 수: 500억 개
- 다이 크기: 645mm²
- 코어 수: 354개 (각 코어는 64비트 슈퍼스칼라 구조)
- 클럭 속도: 2GHz
- SRAM 용량: 총 440MB (코어당 1.25MB)
- 연산 성능:
- BF16 / CFloat8: 최대 376 TFLOPS
- FP32: 약 22 TFLOPS
- 메모리 대역폭:
- 온칩: 10TB/s
- 오프칩: 4TB/s
- 전력 소비: 약 400W위키백과+4Tom's Hardware+4위키백과+4위키백과위키백과+2The Next Platform+2SemiAnalysis+2SemiAnalysis+3위키백과+3위키백과+3TechEBlog+1DataCenterDynamics+1
🧱 아키텍처 및 확장성
- 노드 구조: 각 코어는 64비트 스칼라 및 64바이트 SIMD 벡터 명령어를 지원하며, RISC-V와 커스텀 명령어를 혼합하여 다양한 정수 및 부동소수점 연산을 처리합니다.
- 네트워크 온 칩 (NoC): 2D 메시 구조로 코어 간 고속 통신을 지원하며, 각 방향으로 64바이트의 읽기 및 쓰기 작업을 동시에 수행할 수 있습니다.
- 트레이닝 타일: 25개의 D1 칩을 5×5 배열로 구성한 모듈로, 9 PFLOPS의 연산 성능과 36TB/s의 대역폭을 제공합니다.
- 시스템 트레이: 6개의 트레이닝 타일을 통합하여 구성되며, 53,100개의 코어와 1.3TB의 SRAM, 13TB의 HBM을 포함합니다.
- ExaPOD: 10개의 캐비닛으로 구성되며, 총 120개의 트레이닝 타일과 1,062,000개의 코어를 통해 1.1 EFLOPS의 연산 성능을 달성합니다.Reddit+6위키백과+6위키백과+6위키백과+1위키백과+1TechEBlog+1위키백과+1
🎯 활용 분야
- 자율주행 AI 학습: 테슬라 차량에서 수집된 대규모 비디오 데이터를 활용하여 자율주행 알고리즘을 학습합니다.
- 비디오 기반 신경망 학습: 고해상도 비디오 데이터를 처리하여 객체 인식, 경로 예측 등의 기능을 향상시킵니다.
- 대규모 AI 모델 학습: Transformer 기반의 대규모 언어 모델 및 생성형 AI 모델의 학습에 활용됩니다.
📸 대표 이미지
Dojo D1 칩은 테슬라의 자율주행 기술 발전을 위한 핵심 요소로, 대규모 데이터 처리와 고성능 연산을 통해 AI 모델의 학습 속도와 효율성을 크게 향상시킵니다. 이를 통해 테슬라는 자율주행 기술의 상용화에 한 걸음 더 다가가고 있습니다.
13. (로봇용) Qualcomm QCS8250
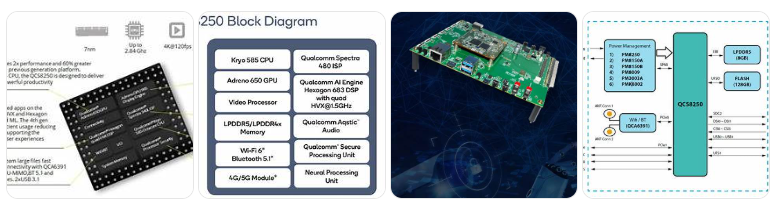
Qualcomm QCS8250는 고성능 엣지 AI 및 비전 중심 IoT 애플리케이션을 위한 프리미엄 SoC(System-on-Chip)입니다. 이 칩은 5G 및 Wi-Fi 6 연결을 지원하며, 스마트 카메라, 비디오 협업, 헬스케어, 스마트 리테일 등 다양한 산업 분야에 적합합니다.atestore.de+2퀄컴+2퀄컴+2
🔧 주요 사양
- CPU: 8코어 Qualcomm Kryo™ 585 (4x 2.85GHz + 4x 1.8GHz)
- GPU: Qualcomm Adreno™ 650
- DSP: Hexagon™ 698 DSP (1.5GHz, Quad HVX)
- AI 성능: 15 TOPS (Hexagon Tensor Accelerator 및 NPU 포함)
- 메모리: LPDDR5 또는 LPDDR4x, 최대 2750MHz
- 스토리지: UFS 3.0, UFS 2.1, SD 3.0 지원
- ISP: Qualcomm Spectra™ 480, 최대 64MP 단일 카메라 또는 최대 7개의 동시 카메라 스트림 지원
- 비디오 처리:
- 인코딩: 최대 8K30 또는 4K120
- 디코딩: 최대 8K60 또는 4K240
- 디스플레이: 최대 3개의 4K 디스플레이 지원
- 연결성:
- Wi-Fi 6 (802.11ax)
- Bluetooth 5.1
- 5G mmWave 및 sub-6GHz (동반 모듈을 통해)
- I/O 인터페이스:
- 2x USB 3.1 (Type-C 포함)
- PCIe (3레인)
- MIPI-CSI/DSI
- UART, I2C, SPI, GPIO 등
- 보안: 전용 보안 처리 유닛(SPU)
- 운영 체제: Android 10 지원Shop@eInfoChips+6excelpoint.com+6atestore.de+6VVDN Technologies+6atestore.de+6excelpoint.com+6VVDN Technologies+7퀄컴+7Arrow+7퀄컴+3excelpoint.com+3atestore.de+3VVDN Technologies+2퀄컴+2퀄컴+2퀄컴+3VVDN Technologies+3VVDN Technologies+3Lantronix+4VVDN Technologies+4VVDN Technologies+4
🎯 주요 특징
- 엣지 AI 및 비디오 분석: 전용 컴퓨터 비전 하드웨어 블록과 Hexagon Tensor Accelerator를 통해 복잡한 AI 및 딥러닝 워크로드를 효율적으로 처리합니다.
- 고급 카메라 지원: 최대 7개의 동시 카메라 스트림 또는 최대 24개의 비디오 스트리밍 카메라를 지원하며, 고급 이미지 품질 기능을 제공합니다.
- 다양한 애플리케이션 지원: 스마트 카메라, 비디오 협업, 디지털 사이니지, 차량 관리, 헬스케어 등 다양한 산업 분야에 적합합니다.퀄컴+3excelpoint.com+3퀄컴+3
🧩 개발 키트 및 모듈
VVDN QCS8250 개발 키트
- 구성: QCS8250 SOM(System on Module) 및 캐리어 보드
- 카메라 인터페이스: 6x 4레인 MIPI CSI
- 디스플레이 인터페이스: 2x 4레인 MIPI DSI
- 메모리: 8GB LPDDR5
- 스토리지: 128GB UFS
- 운영 체제: Android 10
- 연결성: Wi-Fi 6, Bluetooth 5.1, 이더넷Shop@eInfoChips+2Lantronix+2VVDN Technologies+2Shop@eInfoChips+3VVDN Technologies+3VVDN Technologies+3Shop@eInfoChips+3VVDN Technologies+3VVDN Technologies+3excelpoint.com+3퀄컴+3VVDN Technologies+3
eInfochips Aikri QCS8250 개발 키트
- 프로세서: Qualcomm QCS8250
- 메모리: 8GB LPDDR5
- 스토리지: 64GB UFS 2.1
- 카메라 인터페이스: 6x 4레인 MIPI CSI
- 디스플레이 인터페이스: 2x 4레인 MIPI DSI, HDMI 2.0 (도터 보드 통해)
- 연결성: Wi-Fi 6, Bluetooth 5.0, 이더넷
- 운영 체제: Android 10Shop@eInfoChipsLantronix+3VVDN Technologies+3VVDN Technologies+3퀄컴+1퀄컴+1
📸 대표 이미지
Qualcomm QCS8250은 고성능 엣지 AI 및 비전 중심 IoT 애플리케이션을 위한 강력한 솔루션으로, 다양한 산업 분야에서의 활용이 기대됩니다. 개발 키트 및 모듈을 통해 빠른 프로토타이핑과 제품 개발이 가능하며, 장기적인 제품 수명 보장을 통해 안정적인 제품 개발이 가능합니다.
14. (로봇용) Tachy-BS402, 한국 디퍼아이(Deeper-I) 개발 엣지 AI 추론용 SoC(System-on-Chip)

Tachy-BS402는 한국의 AI 반도체 설계 기업 **디퍼아이(Deeper-I)**가 개발한 엣지 AI 추론용 SoC(System-on-Chip)입니다. 이 칩은 TSMC 28nm 공정을 통해 양산되었으며, 에이직랜드와 협력하여 백엔드 설계를 완료하였습니다.다음+2Deeper-I+2톱데일리+2톱데일리+1미래를 보는 창 - 전자신문+1
🔧 주요 사양
- CPU: Arm Cortex-A5 쿼드코어 (400MHz)
- NPU: 듀얼 코어 BlackSwan v1.0 (300MHz)
- 메모리: DDR3 533MHz, NorFlash 지원
- 카메라 인터페이스: 2채널 BT.1120, RGB888, Bayer 포맷 지원
- 외부 인터페이스: USB 2.0, SPI, UART, GPIO 등
🧠 아키텍처 및 특징
- X2X 기술: SoC 간 통신을 원활하게 구현하여 딥러닝 연산을 분산시키며, 음성과 영상 데이터의 동시 처리를 가능하게 합니다.
- 추론 최적화: GPU 기반의 범용 AI 칩보다 효과적으로 학습 데이터를 활용할 수 있으며, 다양한 AI 애플리케이션에 쉽게 알고리즘을 실행할 수 있는 환경을 제공합니다.
- 저전력 설계: 명령의 규모에 맞는 적절한 처리방식을 적용하여 불필요한 전력 소모를 줄이고, 고효율 AI 서비스 환경을 제공합니다.다음+2톱데일리+2미래를 보는 창 - 전자신문+2미래를 보는 창 - 전자신문+1톱데일리+1다음+1톱데일리+1
🧩 활용 분야
- 스마트 비전: 영상 기반의 객체 인식, 이상 탐지 등
- 스마트 모빌리티: 자율주행 차량의 센서 데이터 처리 및 경로 계획
- 스마트 팩토리: 공장 자동화 및 품질 검사 시스템
- 의료: 부정맥 진단 및 예측 등
- 보안: 군 야간감시장비 등톱데일리
📸 대표 이미지
Tachy-BS402는 엣지 AI 애플리케이션에 최적화된 SoC로, 저전력 고효율의 AI 추론 기능을 제공합니다. 디퍼아이는 이 칩을 기반으로 다양한 산업 분야에서의 AI 솔루션을 개발하고 있으며, 향후 다양한 분야로의 확장이 기대됩니다.다음+3톱데일리+3다음+3
15. (5G용) Untether AI의 speedAI®240 Slim

Untether AI의 speedAI®240 Slim은 에너지 효율성과 고성능을 동시에 제공하는 AI 추론 가속기 카드로, 엣지 컴퓨팅 및 온프레미스 데이터센터 환경에 최적화되어 있습니다.untether.ai+12Medium+12untether.ai+12
🔧 주요 사양
- 형태: 저전력, 저프로파일 PCIe 카드
- TDP: 75W
- 아키텍처: At-Memory Compute (AMC)
- 프로세서: 1,400개의 RISC-V 기반 커스텀 코어
- 성능:
- 최대 2 PetaOps (INT8 기준)
- 최대 20 TOPS/W의 에너지 효율성
- 메모리: 204MB의 온칩 SRAM
- 지원 모델: CNN, Transformer, 추천 시스템 등 다양한 AI 모델
- 소프트웨어: imAIgine® SDK를 통한 모델 최적화 및 배포 지원untether.ai+7Medium+7Medium+7untether.ai+1untether.ai+1untether.ai비즈니스 와이어+8untether.ai+8untether.ai+8
📊 MLPerf 벤치마크 성능
speedAI®240 Slim은 MLPerf Inference v4.1 벤치마크에서 다음과 같은 성과를 기록하였습니다:야후 금융+13비즈니스 와이어+13untether.ai+13
- ResNet-50 이미지 분류:
- 오프라인 처리량: 70,348 샘플/초 (단일 PCIe 카드 기준)
- 싱글 스트림 지연 시간: 0.12ms
- 멀티 스트림 지연 시간: 0.17ms
- 에너지 효율성:
- 데이터센터 환경에서 경쟁 제품 대비 3배 높은 에너지 효율성
- 엣지 환경에서 최대 6배 높은 에너지 효율성Medium+3Medium+3비즈니스 와이어+3untether.ai+1비즈니스 와이어+1비즈니스 와이어+1untether.ai+1
이러한 성능은 Untether AI의 AMC 아키텍처가 데이터 이동 병목 현상을 최소화하여 고성능과 저전력을 동시에 달성했음을 보여줍니다.
🚀 활용 분야
speedAI®240 Slim은 다음과 같은 분야에서 활용될 수 있습니다:야후 금융+13untether.ai+13untether.ai+13
- 자동차: 자율주행 차량의 실시간 객체 인식 및 경로 계획
- 농업: 스마트 농업 장비의 작물 모니터링 및 분석
- 비전 AI: 산업용 검사 시스템, 스마트 시티의 영상 분석
- 데이터센터: 온프레미스 AI 추론 가속화
특히, Mercedes-Benz는 자율주행 차량에 speedAI®240 Slim을 통합하기 위해 Untether AI와 협력하고 있습니다.
🧠 기술적 특징
- At-Memory Compute 아키텍처: 연산 유닛을 메모리 셀 근처에 배치하여 데이터 이동을 최소화하고 지연 시간과 전력 소비를 줄입니다.
- RISC-V 기반 설계: 오픈소스 RISC-V 아키텍처를 활용하여 유연성과 확장성을 제공합니다.
- imAIgine® SDK: 트레이닝된 AI 모델을 최적화하여 speedAI®240 Slim에 쉽게 배포할 수 있도록 지원합니다.Medium+14untether.ai+14untether.ai+14
📸 제품 이미지
speedAI®240 Slim은 고성능과 에너지 효율성을 동시에 요구하는 엣지 AI 애플리케이션에 적합한 솔루션으로, 다양한 산업 분야에서의 활용이 기대됩니다. 추가적인 정보나 데모 요청은 Untether AI의 공식 웹사이트를 통해 확인하실 수 있습니다.비즈니스 와이어+5untether.ai+5untether.ai+5
16. (5G) Untether AI의 speedAI®240 Slim

📱 Dimensity 9300 개요
MediaTek Dimensity 9300은 2023년 11월 발표된 프리미엄 안드로이드 스마트폰용 플래그십 모바일 칩셋으로, 고성능과 에너지 효율을 동시에 제공합니다.
🔧 주요 사양
- CPU 아키텍처:
전례 없는 올빅 코어 설계를 채택:- Cortex-X4 3.25GHz 1코어
- Cortex-X4 2.85GHz 3코어
- Cortex-A720 2.0GHz 4코어
- GPU:
12코어 Arm Immortalis-G720 GPU 탑재- 하드웨어 기반 레이 트레이싱 지원
- 게임 및 멀티미디어 그래픽 성능 향상
- AI 프로세서(APU):
APU 790 탑재, 전작 대비- AI 성능 8배 향상
- 전력 소비 45% 절감
- 온디바이스 생성형 AI(Stable Diffusion, LLaMA 2, Baidu LLM 등) 지원
- 메모리 및 저장장치:
- LPDDR5T 메모리 최대 9600 Mbps 지원
- UFS 4.0 스토리지 + MCQ 기술로 초고속 데이터 처리
- 연결성:
- 5G Sub-6GHz 및 mmWave 지원 (최대 7.9Gbps)
- Wi-Fi 7 (2x2 MIMO) 지원
- Bluetooth 5.4 지원
- 카메라 및 디스플레이:
- Imagiq 990 ISP: 최대 3억 2천만 화소 카메라 및 8K 30fps 동영상
- 고해상도 디스플레이 및 가변 주사율 지원
📊 성능 요약
- CPU 성능:
전작 Dimensity 9200 대비- 싱글코어 성능 15%↑
- 멀티코어 성능 40%↑
- GPU 성능:
- 그래픽 성능 46% 향상
- 전력 소비 40% 절감
- 콘솔급 게임 (60FPS) 가능
- AI 능력:
- Stable Diffusion 기반 이미지 생성 1초 이내
- 대규모 언어 모델(LLM) 온디바이스 추론 가능
📱 Dimensity 9300 탑재 대표 스마트폰
- vivo X100 / X100 Pro
- OPPO Find X7
- Xiaomi 14T Pro
Dimensity 9300은 차세대 플래그십 스마트폰에 초고속 연산, 강력한 AI 처리, 최신 5G/무선 기술을 제공하는 전방위 성능 최적화 칩셋으로 자리매김하고 있습니다.
17. (5G) Exynos 2400,는 삼성전자 프리미엄 모바일 SoC(System-on-Chip)

Samsung Exynos 2400는 삼성전자가 2024년 1월 발표한 프리미엄 모바일 SoC(System-on-Chip)로, Galaxy S24 및 S24+ 모델에 탑재되었습니다. 이 칩은 고성능 연산, 향상된 AI 처리 능력, 그리고 AMD RDNA 3 기반 GPU를 통해 전반적인 성능을 크게 향상시켰습니다.
🔧 주요 사양 요약
- 제조 공정: 4nm FinFET (Samsung 4LPP+)
- CPU 구성 (10코어):
- 1x Cortex-X4 @ 3.2GHz
- 2x Cortex-A720 @ 2.9GHz
- 3x Cortex-A720 @ 2.6GHz
- 4x Cortex-A520 @ 1.95GHz
- GPU: Samsung Xclipse 940 (AMD RDNA 3 기반, 6WGP)
- AI 엔진: 17K MAC NPU (2x GNPU + 2x SNPU) 및 DSP 포함
- 메모리: LPDDR5X (최대 8.5Gbps)
- 스토리지: UFS 4.0
- 디스플레이 지원: 최대 4K/WQUXGA @ 120Hz
- 카메라 지원: 최대 320MP, 8K @ 60fps 비디오 촬영
- 통신: 5G Sub-6GHz 및 mmWave, Wi-Fi 6E, Bluetooth 5.3Radargit+3위키백과+3Samsung Semiconductor Global+3NanoReview.net+8위키백과+8Samsung Semiconductor Global+8디바이스 스펙ifications+8GSMArena+8FoneArena+8위키백과+12위키백과+12위키백과+12위키백과+3Samsung Semiconductor Global+3위키백과+3FoneArena위키백과+1Samsung Semiconductor Global+1
📊 벤치마크 성능
- AnTuTu v10: 약 1,744,941점
- Geekbench 6:
- 싱글코어: 2,196점
- 멀티코어: 6,964점
- 3DMark Wild Life:
- 점수: 13,893점
- 그래픽 테스트 1: 83 FPSSamMobile+6NanoReview.net+6Android Authority+6위키백과+1Eureka+1위키백과+11UL 벤치마크+11UL 벤치마크+11
이러한 성능은 Exynos 2200 대비 CPU 성능이 약 70% 향상되었으며, AI 처리 능력은 14.7배 증가한 것으로 나타났습니다. Sam Lover
🎮 GPU 및 게임 성능
Xclipse 940 GPU는 AMD의 RDNA 3 아키텍처를 기반으로 하며, 6개의 워크그룹 프로세서(WGP)를 통해 하드웨어 기반 레이 트레이싱을 지원합니다. 이로 인해 모바일 게임에서 더욱 사실적인 조명, 반사, 그림자 효과를 구현할 수 있습니다. 위키백과+5Sam Lover+5FoneArena+5Samsung Semiconductor Global
🤖 AI 및 NPU 기능
Exynos 2400은 17K MAC NPU를 통해 온디바이스 AI 처리 능력을 크게 향상시켰습니다. 이는 이미지 생성, 음성 인식, 자연어 처리 등 다양한 AI 애플리케이션에서 빠르고 효율적인 성능을 제공합니다. 위키백과+3위키백과+3위키백과+3
📱 탑재 기기
Exynos 2400은 주로 유럽 및 아시아 시장의 Galaxy S24 및 S24+ 모델에 탑재되었으며, S24 Ultra 모델에는 Snapdragon 8 Gen 3가 사용되었습니다. World Today News+4위키백과+4Notebookcheck+4
🔋 배터리 효율성
Exynos 2400을 탑재한 Galaxy S24는 웹 브라우징, 4K 비디오 재생, 게임 실행 등 다양한 사용 시나리오에서 Snapdragon 8 Gen 3 대비 최대 36% 긴 배터리 수명을 보여주었습니다. Android Authority
🧩 요약
| 항목 | 사양 및 특징 |
| 제조 공정 | 4nm FinFET (Samsung 4LPP+) |
| CPU 구성 | 10코어 (1x X4, 5x A720, 4x A520) |
| GPU | Xclipse 940 (AMD RDNA 3 기반) |
| AI 엔진 | 17K MAC NPU 및 DSP |
| 메모리 | LPDDR5X (최대 8.5Gbps) |
| 스토리지 | UFS 4.0 |
| 디스플레이 지원 | 최대 4K/WQUXGA @ 120Hz |
| 카메라 지원 | 최대 320MP, 8K @ 60fps 비디오 촬영 |
| 통신 | 5G Sub-6GHz 및 mmWave, Wi-Fi 6E, Bluetooth 5.3 |
| 배터리 효율성 | Snapdragon 8 Gen 3 대비 최대 36% 향상 |
Exynos 2400은 CPU, GPU, AI 성능, 배터리 효율성 등 여러 측면에서 전작 대비 큰 향상을 이루었으며, 최신 플래그십 스마트폰에서의 고성능 요구를 충족시키는 SoC로 평가받고 있습니다.
18. (5G) Apple C1, iPhone 16e 애플의 자체 개발 5G 셀룰러 모뎀 칩
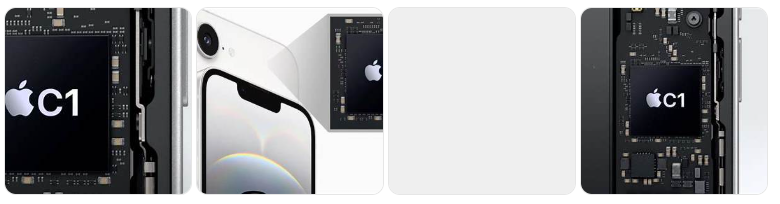
Apple C1는 2025년 2월 출시된 iPhone 16e에 처음 탑재된 애플의 자체 개발 5G 셀룰러 모뎀 칩입니다. 이는 애플이 오랜 기간 의존해온 퀄컴(Qualcomm) 모뎀을 대체하기 위한 전략적 전환점으로, 전력 효율성, 통합 설계, 글로벌 호환성 측면에서 주목받고 있습니다.The Verge+6macerkopf.de+6Apfeltalk Magazin+6
🔧 주요 사양 및 특징
- 제조 공정: 기지대역(Baseband)은 4nm, 트랜시버(Transceiver)는 7nm 공정으로 제작되어 고성능과 저전력 소비를 실현했습니다. telecomstechnews.com+4Computerworld+4MacRumors Forums+4
- 지원 네트워크: 5G Sub-6GHz 및 4G LTE를 지원하며, **mmWave(밀리미터파)**는 지원하지 않습니다.
- 통합 기능: GPS, 위성 통신, Wi-Fi 6, Bluetooth 5.3 등을 하나의 모뎀 시스템에 통합하여 공간 효율성과 성능을 향상시켰습니다.
- 전력 효율성: 퀄컴 모뎀 대비 20~25% 낮은 전력 소비를 실현하여, iPhone 16e의 배터리 수명을 최대 26시간까지 연장시켰습니다. 위키백과+1AppleInsider+1
- 글로벌 호환성: 55개국 180개 통신사와의 테스트를 통해 전 세계적인 호환성을 확보했습니다. Reuters
🤖 A18 칩과의 통합 및 AI 최적화
C1 모뎀은 iPhone 16e에 탑재된 A18 칩과 긴밀하게 통합되어, 네트워크 트래픽을 실시간으로 관리하고 사용자 요구에 따라 우선순위를 조정합니다. 예를 들어, 혼잡한 네트워크 환경에서 사진이나 영상을 전송할 때 A18 칩이 C1 모뎀에 해당 트래픽을 우선 처리하도록 지시하여 사용자 경험을 향상시킵니다. 9to5Mac+1MacRumors Forums+1
📱 iPhone 16e에서의 적용
- 가격: $599로, 기존 SE 모델을 대체하는 보급형 플래그십으로 출시되었습니다. WSJ
- 디자인: 홈 버튼이 제거되고 Face ID가 도입되어 최신 iPhone 디자인을 따릅니다.
- Apple Intelligence: iOS 18의 새로운 AI 기능을 지원하여, 사진 편집, 자연어 검색 등 다양한 기능을 제공합니다. Apple
🔮 향후 전망
- C2 및 C3 개발: 애플은 이미 차세대 모뎀인 C2와 C3를 개발 중이며, 향후 iPhone 17 및 그 이후 모델에 탑재될 예정입니다. AppleInsider
- SoC 통합: 장기적으로는 C 시리즈 모뎀을 A 시리즈 및 M 시리즈 칩셋에 통합하여, iPhone뿐만 아니라 Mac 등 다른 애플 기기에서도 자체 모뎀을 사용할 계획입니다. AppleInsider
Apple C1은 애플이 통신 기술에서도 독립성을 확보하려는 전략의 일환으로, 향후 애플 생태계 전반에 걸쳐 중요한 역할을 할 것으로 기대됩니다. 특히 전력 효율성과 통합 설계 측면에서의 강점은 향후 다양한 애플 제품에 긍정적인 영향을 미칠 것입니다.
19. (5G) Marvell OCTEON 10 Fusion, 5G 무선 인프라 5nm 기반의 베이스밴드 프로세서 제품군

Marvell OCTEON 10 Fusion은 5G 무선 인프라를 위한 고성능 및 에너지 효율성을 갖춘 5nm 기반의 베이스밴드 프로세서 제품군입니다. 이 칩은 전통적인 일체형 기지국 설계뿐만 아니라 가상화된 RAN(vRAN) 및 O-RAN 아키텍처를 지원하도록 최적화되어 있습니다.Marvell+6Marvell+6Marvell+6Marvell+2Marvell+2Marvell+2
🔧 주요 사양 및 특징
- 제조 공정: 업계 최초의 5nm 베이스밴드 프로세서로, 뛰어난 성능과 에너지 효율성을 제공합니다. Marvell
- CPU 아키텍처: 64비트 Arm Neoverse N2 코어를 기반으로 하며, 최대 24개의 코어를 지원합니다. Marvell+8TechPowerUp+8cloudswit.ch+8
- 하드웨어 가속기: 5G 베이스밴드, 네트워킹 및 보안을 위한 다양한 하드웨어 가속기를 통합하고 있습니다. 특히, 인라인 AI/ML 엔진을 통해 RAN 애플리케이션에서 효율적인 엣지 추론을 지원합니다. Marvell+3Marvell+3Marvell+3
- 메모리 및 I/O: 최대 6개의 DDR5 메모리 채널(최대 5600 MT/s)과 PCIe 5.0 인터페이스를 지원하여 고속 데이터 전송을 가능하게 합니다. Marvell
- 네트워크 인터페이스: 최대 16개의 50G 이더넷 MAC을 지원하며, 통합된 1Tbps 스위치를 통해 고속 네트워크 처리를 제공합니다. AnandTech
- 보안 기능: 인라인 암호화(IPSec/SSL) 및 하드웨어 기반의 보안 부팅(Secure Boot)을 지원하여 데이터 보안을 강화합니다. Marvell
📡 5G RAN 아키텍처 지원
OCTEON 10 Fusion은 다양한 5G RAN 아키텍처를 지원하며, 다음과 같은 구성에서 활용될 수 있습니다:TechPowerUp+3Marvell+3Marvell+3
- 일체형 기지국: 전통적인 매크로 셀 기지국 설계에 적합합니다.
- 가상화된 RAN(vRAN): 소프트웨어 정의 네트워크 환경에서의 유연한 배포를 지원합니다.
- O-RAN 아키텍처: 개방형 인터페이스를 통해 다양한 공급업체의 장비와의 상호 운용성을 제공합니다.
또한, Massive MIMO 및 mmWave를 포함한 다양한 주파수 대역에서의 운영을 지원하여 글로벌 5G 배포에 적합합니다. Marvell
🔋 에너지 효율성 및 성능
OCTEON 10 Fusion은 이전 세대 대비 시스템 용량이 두 배로 증가하였으며, 전력 소비는 50% 감소하여 뛰어난 에너지 효율성을 제공합니다. Marvell
🤝 생태계 및 협력
Marvell은 Dell, Samsung, Nokia, Fujitsu 등 주요 OEM 및 클라우드 서비스 제공업체와 협력하여 OCTEON 10 Fusion 기반의 솔루션을 개발하고 있습니다. 이러한 협력을 통해 다양한 5G RAN 배포 시나리오에 최적화된 솔루션을 제공합니다. Marvell+2Marvell+2TechPowerUp+2
Marvell OCTEON 10 Fusion은 고성능, 에너지 효율성, 유연한 아키텍처 지원을 통해 5G 네트워크의 다양한 요구를 충족시키는 솔루션으로, 차세대 무선 인프라 구축에 핵심적인 역할을 할 것으로 기대됩니다.



20. (5G) NXP Layerscape Access, NXP Semiconductors 통신 인프라용 SoC(System-on-Chip)
NXP Layerscape Access
NXP Layerscape Access는 NXP Semiconductors가 개발한 통신 인프라용 SoC(System-on-Chip) 제품군으로, 특히 5G 및 LTE 네트워크의 기지국, 소형 셀, 고정 무선 액세스(FWA) 장비에 최적화되어 있습니다. 이 제품군은 고성능 ARM 프로세서와 통합된 베이스밴드 및 네트워크 가속기를 통해 다양한 통신 기능을 제공합니다.
🔧 주요 제품 및 사양
1. Layerscape Access LA12xx 시리즈
- 용도: 5G 및 LTE 기지국의 DU(Distributed Unit), 소형 셀, FWA 장비
- CPU: 최대 4개의 Arm Cortex-A72 코어
- 베이스밴드: 통합된 5G NR 및 LTE PHY 지원
- 가속기: 하드웨어 기반의 패킷 처리 및 보안 가속기
- 연결성: 최대 10Gbps 이더넷, PCIe, USB 3.0
- 특징: 소형 폼 팩터, 저전력 설계, vRAN 및 O-RAN 아키텍처 지원
2. Layerscape Access LA1575
- 용도: 고성능 5G 기지국 및 네트워크 장비
- CPU: 최대 8개의 Arm Cortex-A72 코어
- 베이스밴드: 5G NR 및 LTE PHY 통합
- 가속기: 고속 패킷 처리, 보안, QoS 가속기
- 연결성: 최대 25Gbps 이더넷, PCIe Gen4, USB 3.1
- 특징: 고성능, 확장성, 다양한 네트워크 아키텍처 지원
📡 주요 기능 및 장점
- 통합 설계: CPU, 베이스밴드, 네트워크 가속기를 하나의 칩에 통합하여 공간 절약 및 성능 향상
- 유연한 아키텍처 지원: vRAN, O-RAN, 전통적인 RAN 아키텍처 모두 지원
- 에너지 효율성: 저전력 설계를 통해 운영 비용 절감
- 보안 기능: 하드웨어 기반의 보안 부팅, 암호화 가속기 등으로 강화된 보안
- 확장성: 다양한 제품군을 통해 소형 셀부터 대형 기지국까지 다양한 용도에 대응
🧩 활용 사례
- 5G 기지국: DU 및 CU 장비에 통합되어 고속 데이터 처리 및 전송 지원
- 소형 셀: 도시 지역의 밀집된 사용자 환경에서 효율적인 커버리지 제공
- 고정 무선 액세스(FWA): 광대역 인터넷 서비스 제공을 위한 고성능 CPE 장비
- 산업용 IoT: 스마트 팩토리, 스마트 시티 등에서의 안정적인 통신 인프라 구축
NXP Layerscape Access 제품군은 통신 인프라의 다양한 요구사항을 충족시키는 유연성과 성능을 제공하며, 5G 시대의 다양한 응용 분야에 적합한 솔루션을 제공합니다.
21. (5G) Intel Xeon D-2700 시리즈, Ice Lake-D 아키텍처 기반의 SoC(System-on-Chip)
Intel Xeon D-2700 시리즈는 2022년 MWC에서 발표된 Ice Lake-D 아키텍처 기반의 SoC(System-on-Chip) 제품군으로, 엣지 컴퓨팅, 통신 인프라, 산업 자동화, 방산 등 다양한 분야에 최적화된 고성능 프로세서입니다.
🔧 주요 사양 요약
| 마이크로아키텍처 | Ice Lake-D (10nm) |
| 코어 수 | 4~20코어 / 최대 40스레드 |
| 클럭 속도 | 기본 1.8GHz~2.5GHz / 터보 최대 3.5GHz |
| L3 캐시 | 최대 30MB |
| TDP | 65W ~ 129W |
| 메모리 지원 | 최대 1TB DDR4 ECC / 최대 4채널 / 최대 3200MT/s |
| I/O 인터페이스 | 최대 64개 PCIe 4.0 레인 / 최대 100GbE 이더넷 / USB 3.0 등 |
| 보안 기능 | Intel QAT, Secure Boot, 암호화 가속기 등 |
| AI/ML 지원 | AVX-512, VNNI 등 AI 가속 지원 |
| 운영 환경 | -40°C ~ 85°C의 산업용 환경 지원 |
| 소켓 타입 | FCBGA2579 |
🧩 활용 분야
- 엣지 컴퓨팅: 고성능 연산과 다양한 I/O 옵션을 통해 실시간 데이터 처리 및 분석에 적합합니다.
- 통신 인프라: 5G 네트워크의 DU(Distributed Unit) 및 CU(Centralized Unit) 장비에 활용되어 고속 데이터 전송과 처리에 기여합니다.
- 산업 자동화: 산업용 제어 시스템에서의 안정적인 운영과 높은 연산 성능을 제공합니다.
- 방산 및 항공우주: 극한의 환경에서도 안정적인 성능을 유지하며, 보안 기능을 통해 민감한 데이터 보호에 기여합니다.
Intel Xeon D-2700 시리즈는 고성능, 에너지 효율성, 다양한 I/O 옵션, 강화된 보안 기능을 통해 다양한 산업 분야에서의 요구를 충족시키는 솔루션으로 평가받고 있습니다.
